

We sat down with Satya Gupta, Virsec's CTO and Founder, as well as the creator of the Virsec Security Platform, to discuss the technical details of application-aware workload protection.
What Does Application-Aware Mean?
"Application awareness” is an important term to understand. Having effective application-aware protection on your workloads means that you are able to map the acceptable execution of each application and protect them at the memory level during runtime. Your security solution then ensures that the components of those applications are correct and unmodified before they can execute and during runtime. Any deviation from the norm is instantly detected, treated as a threat, and blocked.
Runtime Protection
We must be able to protect the application at runtime and be able to do so in an application-aware manner. We must be able to identify when the bad guys are injecting code or manipulating processes, and stop them from hijacking servers and derailing applications. This is not possible unless you are application-aware; if you don't know what your application is supposed to do, then you cannot recognize when it deviates from its expected execution.
Virsec AppMap® Technology
Virsec's powerful technology can automatically map applications in-depth across the complete application stack. Virsec’s patented AppMap® technology automatically identifies the correct files, scripts, directories, libraries, inputs, processes, memory usage, and more. This comprehensive application-awareness protects workloads in any environment and is applied in real-time, as application code executes.
With Virsec’s unique AppMap® technology, you don’t need to use multiple tools to hunt for threats or spend time determining what threat is happening – the solution already recognizes there is a threat the moment the code deviates and blocks it.
Essential Components of Application-Aware Protection
Our application-aware solution can be understood by defining its nine essential components, or steps.
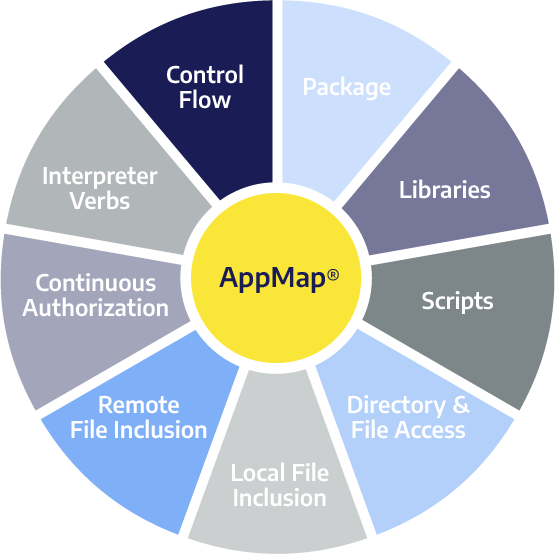
Package
We start off by looking at the packages in which the application is released. We decompose the application, the RPMs, and the MSI. And the package the application is in, the checksums of all the files that are part of that package, that becomes the source of truth that comes from a developer.
Libraries
And then we move on from those executables that we find in the package, we extract what libraries will get loaded into those executables. A new process starts out with a certain executable, which has enough information buried in it to be able to predict which libraries will get loaded. Then we extract that information, so we map or define what packages and what libraries we could be running.
Scripts
We also ascertain the scripts. There are two aspects to consider: there's an allowed list and a disallowed list of scripts. There's a combination of interpreted scripts that are allowed to run – typically IT Ops have certain power shell scripts that they like to be able to run from time to time on that box. And some applications may also have some scripts that may be allowed to run. These are all characterized by change management, and most companies will have this change management mechanism by which they describe how an application would run.
Remote File Inclusion
Now that we have captured all this information, then we move on to remote file inclusion. This is every process that can talk to other endpoints on the network (if they are going to be talking). We extract that information by running the application and extracting that information from the application's runtime.
Local File Inclusion
Local file inclusion describes the directories typically for a web application, where the web root of the application is located and where are all the good file objects would be in that particular directory. With this information, we create a hierarchical map of how the application's code executes. Then, when the bad guys come in and drops some webshells or other such things, then we know it is an alien file.
Directory and File Access
Based on the process memory, we can extract what files are loaded in the memory, and then we can put a little envelope around the application with a particular process, and then we'll define that these processes will touch these XYZ files and directories. Essentially, we create a little straitjacket within which the application executes. People who have done any work with SE limits would be very familiar with this concept.
Continuous Authorization
In many applications, especially legacy applications, there are rules-based access control. Some rules are a little bit more privileged than the other ones. Imagine the HR director at a large Fortune 100 company. They have access to all kinds of privileged information about individual employees, financials, and so forth. We want to make sure that if a company has a legacy application that was not built with two-factor protection to protect the application, for example, that we can still make sure the person who's accessing these privileged URLs is exactly who they say they are. We can then put this runtime control into play with a continuous authorization map.
Interpreter Verbs
Most web applications are written in some sort of a bytecode. A threat actor will attack a bytecode-based application differently than a binary code application. Typically, they'll try to manipulate data that's going into the application that will then turn into some syntax for a downstream interpreter – like a SQL interpreter, JavaScript interpreter, or an OS command – there are many interpreters. We then capture those to make sure that the user input does not contain any such information.
Control Flow
Our control flow map essentially describes how the application should run, targeting binary execution. To understand this, let’s dig into binary executables, which are protected by particular mechanisms. The branches and the code execute – hopping from one branch to the next to the next, which we can observe from the code. So we extract from the code itself, and we are able to define a “manifest” for how each application should run, establishing guardrails around each application as it executes in runtime.
Preventing Remote Code Execution
An attacker’s intention is to be able to perform some form of remote code execution to run foreign code in your environment. The key to detecting foreign code is to be able to stop the attacker’s ability to run this code. We should make sure initially that the application we’re starting with is pristine, that it's what the developer wanted us to run in the first place.
If you look at a typical web application, for example, it has a mixture of code. If we assume that 60-percent of your code is framework code, which is basically written in some compiled language, then the rest of it is interpreted code, which is written into bytecode. So, with a mixture of procedures running bytecode and binary code, if you look inside an application, you'll find hundreds of threads that are running multiple processes that are complex and increase the attackable surface of the application.
We want to make sure that the attacker is not sending bytecode into their request so that the bytecode becomes compromised. And if it's a binary application, then we need to make sure that the application is not sending shell code, which is basically another word for code that looks like data as it's coming in.
Finite Code Vs. Infinite Data
There is a finite amount of code in an application, but the amount of data that can come in is infinite. For example, billions of people all over the world might be interacting with an application, especially those that are on the Internet 24/7. It's impossible to characterize every piece of traffic that's coming in. But characterizing code is a whole lot simpler, because if you look at a given application – say in an Apache server or a Linux server or a Tomcat server – there’s only so much code there. It's a bounded problem as opposed to tearing after data, which is an unbounded problem.
Conventional Security Tools Do Not Provide Application-Aware Protection
Every day, approximately 350,000 pieces of malware are created per day. That means that every EDR tool must have access to all 350,000 of those pieces of malware each day, and they must know exactly how each individual piece of malware is running - an impossible task.
As more and more people realize that this is an endless problem, that companies will just be writing blank checks to security vendors who are providing these services, eventually we will realize that conventional security tools are not sufficient to combat evasive attacks.
Chasing threats, trying to chase the horses after they've left the barn, trying to guess what's coming next – only seems logical if you don't have an alternative. And newer detection and response tools that are claiming they can see threats are only looking at breadcrumbs; they're looking at it after the fact. Or if we’re relying on prior knowledge and signatures, expecting to see some behavior, or in the case of post-exploitation EDR tools that use indicators of compromise – these models failed us miserably with SolarWinds. It doesn't mean they're bad technology, it just means they are not capable of stopping this next generation of attacks - without prior knowledge.
It's like sticking your head in the sand and saying that threat actors will simply execute the same thing over and over and over again; that is really underestimating the capabilities of these hackers. They are sophisticated, smart – many have PhDs – they’re well-funded, highly motivated, and they've got only one thing on their mind: how to break into your system.
Instead, if you protect the application itself from the inside, mapping it and understanding it, and guard railing it from doing the wrong thing, regardless of vulnerabilities, regardless of lack of patching, and regardless of prior knowledge. We define how each application should run and establishing guardrails around it as it executes in runtime. Then any deviation from normal is immediately detected, treated as a threat, and blocked.
Additional Learning
White Paper: The Need for Application-Aware Workload Protection
White Paper: Virsec Zero Trust Workload Protection
Solution Brief: Virsec Security Platform
Webinar: Defending Against Nation-State Attacks: Breaking the Kill Chain
Webinar: SolarWinds CSI: Re-creating the SolarWinds Attack


